LCVT
Latinized CVT Datasets
LCVT
is a dataset directory which
contains points generated
by "Latinizing" an M-dimensional Centroidal Voronoi Tessellation.
Each dataset contains N points in M-dimensions, contained with
the unit hypercube, and with the centered Latin hypercube property,
namely, that for each coordinate 1 <= I <= M, and each of the N
intervals of the form [(J-1)/N,J/N], for 1 <= J <= N, there is
exactly one point K whose I-th coordinate lies at the center of
that interval.
It's actually pretty easy to generate datasets with this property.
For example, there is a "diagonal dataset" that works, and whose
first point has all coordinates equal to 1/(2*N), the second point
has all coordinates equal to 3/(2*N) and so on. Other examples
abound, but they usually do relatively poorly in terms of point
distribution in the original M-dimensional space.
A Latinized CVT attempts to achieve good dispersion in two
opposing senses, first in the Latin hypercube sense (which
considers each dimension separately, and which is achieved
exactly by these datasets), and secondly in the CVT sense,
which considers dispersion in the original M-dimensional space,
and is approximately achieved by the starting CVT dataset
used to begin the Latin computation, but which we can only
hope the final Latinized set roughly "inherits".
The datasets are distinguished by the values of the following
parameters:
-
M, the spatial dimension;
-
N, the number of points to generate;
-
SEED, the initial seed for the random number routine;
-
INITIALIZE, UNIFORM/RANDOM/HALTON/GRID/FILE, the method of
initializing the generators;
-
SAMPLE, UNIFORM/RANDOM/HALTON/GRID, the method of sampling
the Voronoi diagram;
-
SAMPLE_NUM, the number of points used to sample the
region to estimate area, energy, and the Voronoi diagram;
-
CVT_IT, the number of CVT iteration steps;
-
CVT_ENERGY, the clustering energy of the CVT dataset used to
initialize the final Latin computation;
-
LATIN_IT, the number of Latin iteration steps;
-
LATIN_ENERGY, the clustering energy of the final Latinized
CVT dataset;
The values of M and N are specified in the dataset file names.
The values of the clustering energy are approximated by averaging
the squared distance between each sampling point and the nearest
element of the dataset.
Licensing:
The computer code and data files described and made available on this web page
are distributed under
the GNU LGPL license.
Related Data and Programs:
CVT,
a dataset directory which
contains examples of CVT (Centroidal
Voronoi Tessellation) datasets.
LATIN_CENTER,
a dataset directory which
contains examples of
Latin Center datasets.
LATIN_EDGE,
a dataset directory which
contains examples of
Latin Edge datasets.
LATIN_RANDOM,
a dataset directory which
contains examples of
Latin Random datasets.
LCVT,
a C++ library which
computes a Latinized Centroidal Voronoi Tessellation (CVT).
LCVT_DATASET,
a C++ program which
computes a Latinized Centroidal Voronoi Tessellation (CVT) and writes it to a file.
LCVTP,
a dataset directory which
contains examples of
Latinized CVT's on periodic regions.
PLOT_POINTS,
a FORTRAN90 program which
can plot two dimensional
datasets, making Encapsulated PostScript images.
TABLE_LATINIZE,
a FORTRAN90 program which
can
read a TABLE file of points and "latinize" the points,
that is, "gently" rearranging them so that they are regularly
spaced in every coordinate direction.
TABLE_TOP,
a FORTRAN90 program which
can be used to analyze
datasets of any dimension, by creating images of pairwise
coordinates.
Example dataset:
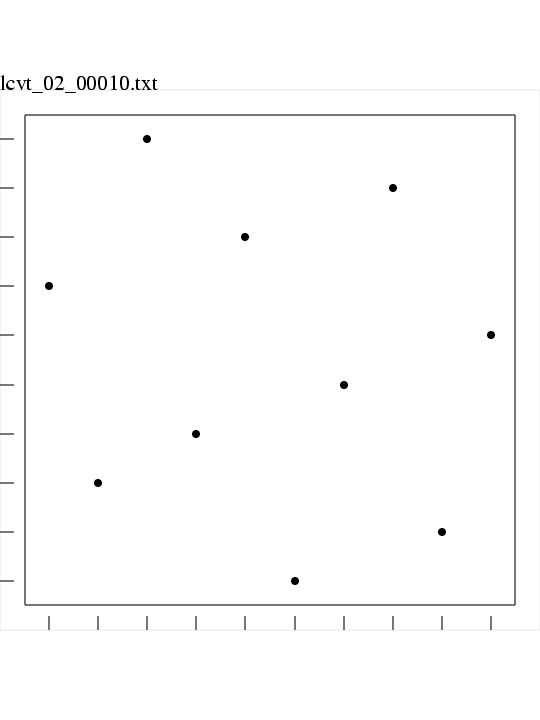
A typical (but small) dataset looks like this:
# lcvt_02_00010.txt
# created by routine LCVT_WRITE in LCVT_DATASET.F90
# at November 12 2003 4:33:43.028 PM
#
# Spatial dimension M = 2
# Number of points N = 10
# EPSILON (unit roundoff) = 0.119209E-06
#
# Initial SEED = 123456789
#
# Initialization by UNIFORM.
# Sampling by UNIFORM.
# Number of sample points = 500000
# Number of CVT iterations = 25
# Energy of CVT dataset = 0.168880E-01
# Number of Latin iterations = 10
# Energy of Latinized CVT dataset = 0.192302E-01
#
0.150000 0.250000
0.450000 0.050000
0.750000 0.150000
0.650000 0.650000
0.250000 0.550000
0.850000 0.850000
0.350000 0.950000
0.950000 0.450000
0.550000 0.350000
0.050000 0.750000
Reference:
-
John Burkardt, Max Gunzburger, Janet Peterson and Rebecca Brannon,
User Manual and Supporting Information for Library of Codes
for Centroidal Voronoi Placement and Associated Zeroth,
First, and Second Moment Determination,
Sandia National Laboratories Technical Report SAND2002-0099,
February 2002.
Online ordering
-
Charles Colbourn, Jeffrey Dinitz,
CRC Handbook of Combinatorial Designs,
CRC Press, 1996,
ISBN: 0849389488.
-
Qiang Du, Vance Faber, Max Gunzburger,
Centroidal Voronoi Tessellations: Applications and Algorithms,
SIAM Review,
Volume 41, Number 4, December 1999, pages 637-676.
-
Michael McKay, William Conover, Richard Beckman,
A Comparison of Three Methods for Selecting Values of Input
Variables in the Analysis of Output From a Computer Code,
Technometrics,
Volume 21, 1979, pages 239-245.
-
Herbert Ryser,
Combinatorial Mathematics,
Mathematical Association of America, 1963,
ISBN: 0883850141,
LC: QA165.R95.
Datasets:
The first family of datasets in M = 2 dimensions include:
-
lcvt_02_00010.txt,
M = 2, N = 10, SEED = 123456789, INITIALIZE = UNIFORM,
SAMPLE = UNIFORM, SAMPLE_NUM = 500,000,
CVT_IT = 25, CVT_ENERGY = 0.017054,
LATIN_IT = 5, LATIN_ENERGY = 0.019797;
-
lcvt_02_00010.png,
a PNG image of
the dataset;
-
lcvt_02_00100.txt,
M = 2, N = 100, SEED = 123456789, INITIALIZE = UNIFORM,
SAMPLE = UNIFORM, SAMPLE_NUM = 500,000,
CVT_IT = 25, CVT_ENERGY = 0.001694,
LATIN_IT = 5, LATIN_ENERGY = 0.001847;
-
lcvt_02_00100.png,
a PNG image of
the dataset;
-
lcvt_02_01000.txt,
M = 2, N = 1000, SEED = 123456789, INITIALIZE = UNIFORM,
SAMPLE = UNIFORM, SAMPLE_NUM = 500,000,
CVT_IT = 25, CVT_ENERGY = 0.000164,
LATIN_IT = 5, LATIN_ENERGY = 0.000169;
-
lcvt_02_01000.png,
a PNG image of
the dataset;
-
lcvt_02_10000.txt,
M = 2, N = 10000, SEED = 123456789, INITIALIZE = UNIFORM,
SAMPLE = UNIFORM, SAMPLE_NUM = 500,000,
CVT_IT = 25, CVT_ENERGY = 0.000017,
LATIN_IT = 5, LATIN_ENERGY = 0.000017;
A second family of datasets in M = 2 dimensions was computed
using different seeds:
-
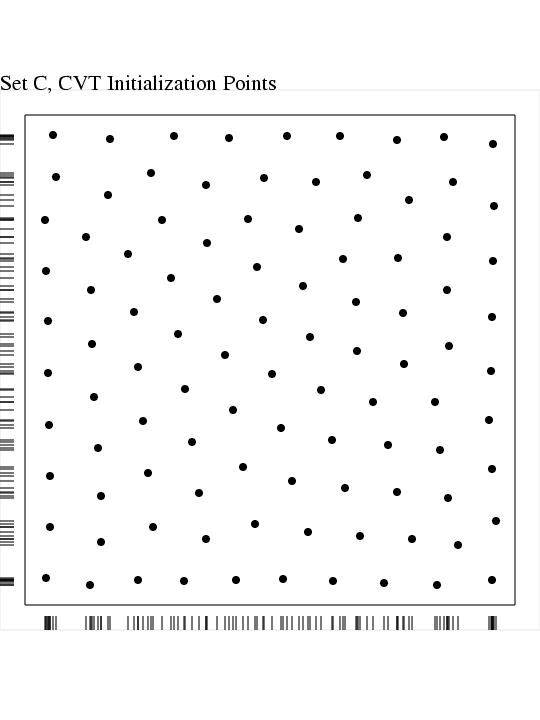
lcvt_02_00100_a.inp,
the LCVT_DATASET input file used to create the dataset;
-
lcvt_02_00100_a_cvt.txt,
the CVT points used for initialization;
-
lcvt_02_00100_a_cvt.png,
a PNG image of
the CVT points;
-
lcvt_02_00100_a.txt,
M = 2, N = 100, SEED = 123456789, INITIALIZE = UNIFORM,
SAMPLE = UNIFORM, SAMPLE_NUM = 500,000,
CVT_IT = 25, CVT_ENERGY = 0.162748E-02,
LATIN_IT = 5, LATIN_ENERGY = 0.173777E-02;
-
lcvt_02_00100_a.png,
a PNG image of
the Latinized CVT points;
-
lcvt_02_00100_b.inp,
the LCVT_DATASET input file used to create the dataset;
-
lcvt_02_00100_b_cvt.txt,
the CVT points used for initialization;
-
lcvt_02_00100_b_cvt.png,
a PNG image of
the CVT points;
-
lcvt_02_00100_b.txt,
M = 2, N = 100, SEED = 987654321, INITIALIZE = UNIFORM,
SAMPLE = UNIFORM, SAMPLE_NUM = 500,000,
CVT_IT = 25, CVT_ENERGY = 0.168769E-02,
LATIN_IT = 5, LATIN_ENERGY = 0.188205E-02;
-
lcvt_02_00100_b.png,
a PNG image of
the Latinized CVT points;
-
lcvt_02_00100_c.inp,
the LCVT_DATASET input file used to create the dataset;
-
lcvt_02_00100_c_cvt.txt,
the CVT points used for initialization;
-
lcvt_02_00100_c_cvt.png,
a PNG image of
the CVT points;
-
lcvt_02_00100_c.txt,
M = 2, N = 100, SEED = 192837465, INITIALIZE = UNIFORM,
SAMPLE = UNIFORM, SAMPLE_NUM = 500,000,
CVT_IT = 25, CVT_ENERGY = 0.165052E-02,
LATIN_IT = 5, LATIN_ENERGY = 0.179708E-02;
-
lcvt_02_00100_c.png,
a PNG image of
the Latinized CVT points;
The first family of datasets in M = 3 dimensions include:
-
lcvt_03_00010.txt,
M = 3, N = 10, SEED = 123456789, INITIALIZE = UNIFORM,
SAMPLE = UNIFORM, SAMPLE_NUM = 500,000,
CVT_IT = 25, CVT_ENERGY = 0.066311,
LATIN_IT = 2, LATIN_ENERGY = 0.068743;
-
lcvt_03_00100.txt,
M = 3, N = 100, SEED = 123456789, INITIALIZE = UNIFORM,
SAMPLE = UNIFORM, SAMPLE_NUM = 500,000,
CVT_IT = 25, CVT_ENERGY = 0.011400,
LATIN_IT = 2, LATIN_ENERGY = 0.013140;
-
lcvt_03_01000.txt,
M = 3, N = 1000, SEED = 123456789, INITIALIZE = UNIFORM,
SAMPLE = UNIFORM, SAMPLE_NUM = 500,000,
CVT_IT = 25, CVT_ENERGY = 0.002437,
LATIN_IT = 2, LATIN_ENERGY = 0.002592;
-
lcvt_03_10000.txt,
M = 3, N = 10000, SEED = 123456789, INITIALIZE = UNIFORM,
SAMPLE = UNIFORM, SAMPLE_NUM = 500,000,
CVT_IT = 25, CVT_ENERGY = 0.000529,
LATIN_IT = 2, LATIN_ENERGY = 0.000543;
The first family of datasets in M = 7 dimensions include:
-
lcvt_07_00010.txt,
M = 7, N = 10, SEED = 123456789, INITIALIZE = UNIFORM,
SAMPLE = UNIFORM, SAMPLE_NUM = 500,000,
CVT_IT = 25, CVT_ENERGY = 0.343148,
LATIN_IT = 2, LATIN_ENERGY = 0.445605;
-
lcvt_07_00100.txt,
M = 7, N = 100, SEED = 123456789, INITIALIZE = UNIFORM,
SAMPLE = UNIFORM, SAMPLE_NUM = 500,000,
CVT_IT = 25, CVT_ENERGY = 0.155165,
LATIN_IT = 2, LATIN_ENERGY = 0.229383;
-
lcvt_07_01000.txt,
M = 7, N = 1000, SEED = 123456789, INITIALIZE = UNIFORM,
SAMPLE = UNIFORM, SAMPLE_NUM = 500,000,
CVT_IT = 25, CVT_ENERGY = 0.079601,
LATIN_IT = 2, LATIN_ENERGY = 0.094108;
-
lcvt_07_10000.txt,
M = 7, N = 10000, SEED = 123456789, INITIALIZE = UNIFORM,
SAMPLE = UNIFORM, SAMPLE_NUM = 500,000,
CVT_IT = 25, CVT_ENERGY = 0.040774,
LATIN_IT = 2, LATIN_ENERGY = 0.045106;
The first family of datasets in M = 16 dimensions include:
-
lcvt_16_00010.txt,
M = 16, N = 10, SEED = 123456789, INITIALIZE = UNIFORM,
SAMPLE = UNIFORM, SAMPLE_NUM = 500,000,
CVT_IT = 25, CVT_ENERGY = 1.057923,
LATIN_IT = 2, LATIN_ENERGY = 1.451406;
-
lcvt_16_00100.txt,
M = 16, N = 100, SEED = 123456789, INITIALIZE = UNIFORM,
SAMPLE = UNIFORM, SAMPLE_NUM = 500,000,
CVT_IT = 25, CVT_ENERGY = 0.828592,
LATIN_IT = 2, LATIN_ENERGY = 1.042796;
-
lcvt_16_01000.txt,
M = 16, N = 1000, SEED = 123456789, INITIALIZE = UNIFORM,
SAMPLE = UNIFORM, SAMPLE_NUM = 500,000,
CVT_IT = 25, CVT_ENERGY = 0.590259,
LATIN_IT = 2, LATIN_ENERGY = 0.714075;
-
lcvt_16_10000.txt,
M = 16, N = 10000, SEED = 123456789, INITIALIZE = UNIFORM,
SAMPLE = UNIFORM, SAMPLE_NUM = 500,000,
CVT_IT = 25, CVT_ENERGY = 0.415456,
LATIN_IT = 2, LATIN_ENERGY = 0.502405;
You can go up one level to
the DATASETS directory.
Last revised on 02 November 2005.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}