CVT
Centroidal Voronoi Tessellation Datasets
CVT
is a dataset directory which
contains points generated
by an M-dimensional Centroidal Voronoi Tessellation.
Each dataset contains N points in M-dimensions, with the
points having the property that they are (approximately)
the centroids of the Voronoi regions that they generate.
The datasets are distinguished by the values of the following
parameters:
-
M, the spatial dimension;
-
N, the number of points to generate;
-
SEED, the initial seed for the random number routine;
-
INITIALIZE, UNIFORM/HALTON/GRID/FILE, the method of
initializing the generators;
-
SAMPLE, UNIFORM/HALTON/GRID, the method of sampling
the Voronoi diagram;
-
SAMPLE_NUM, the number of points used to sample the
Voronoi diagram;
-
ITERATIONS, the number of CVT iteration steps;
The values of M and N are specified in the dataset file names.
The dataset also lists CHANGE, the L2 norm of the dataset
change on the last step, that is the square root of the sum of
the squares of the differences between the coordinates of the
points before and after the last iterative step.
Licensing:
The computer code and data files described and made available on this web page
are distributed under
the GNU LGPL license.
Related Data and Programs:
CVT,
a C++ library which
computes elements of a Centroidal Voronoi Tessellation (CVT).
CVT_DATASET,
a C++ program which
computes a Centroidal Voronoi Tessellation (CVT) and writes it to a file.
PLOT_POINTS,
a FORTRAN90 program which
can plot two dimensional
datasets, making Encapsulated PostScript images.
TABLE_TOP,
a FORTRAN90 program which
can be used to analyze
datasets of any dimension, by creating images of pairwise
coordinates.
Example dataset:
A typical (but small) CVT dataset looks like this:
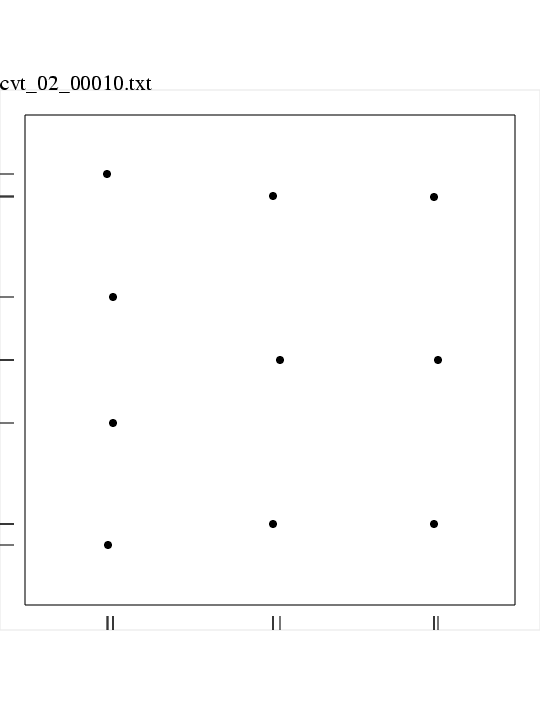
# cvt_02_00010.txt
# created by CVT_DATASET
# at April 11 2003 12:04:56.303 PM
#
# Spatial dimension M = 2
# Number of points N = 10
#
# Initial SEED = 123456789
# Initialization by UNIFORM.
# Sampling by UNIFORM.
# Number of sample points = 500000
# Number of sampling iterations = 100
# L2 norm of dataset change on last step = 0.001501
#
0.168259 0.878328
0.834417 0.833004
0.521361 0.499896
0.506248 0.165244
0.180542 0.627410
0.179467 0.372410
0.505360 0.833925
0.834464 0.166314
0.841834 0.499935
0.169745 0.122347
Reference:
-
John Burkardt, Max Gunzburger, Janet Peterson and Rebecca Brannon,
User Manual and Supporting Information for Library of Codes
for Centroidal Voronoi Placement and Associated Zeroth,
First, and Second Moment Determination,
Sandia National Laboratories Technical Report SAND2002-0099,
February 2002.
-
Qiang Du, Vance Faber, and Max Gunzburger,
Centroidal Voronoi Tessellations: Applications and Algorithms,
SIAM Review, Volume 41, 1999, pages 637-676.
Datasets:
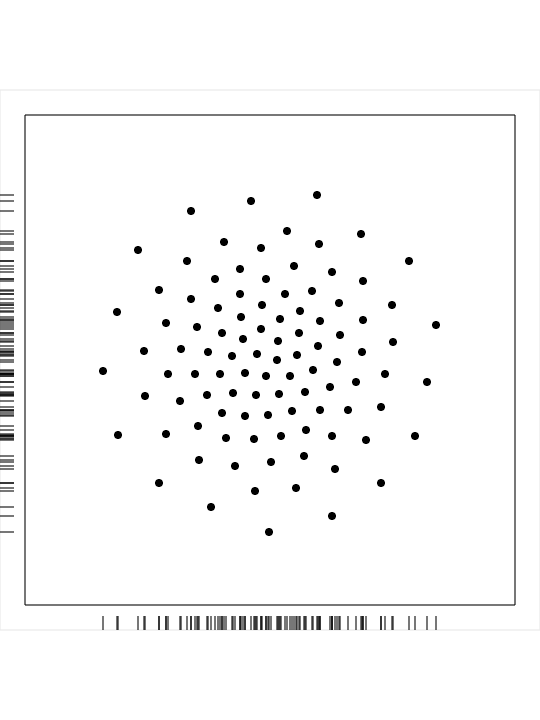
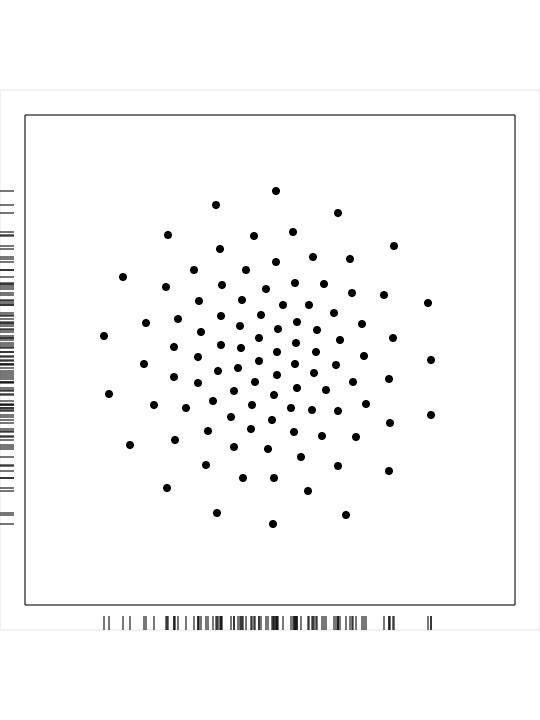
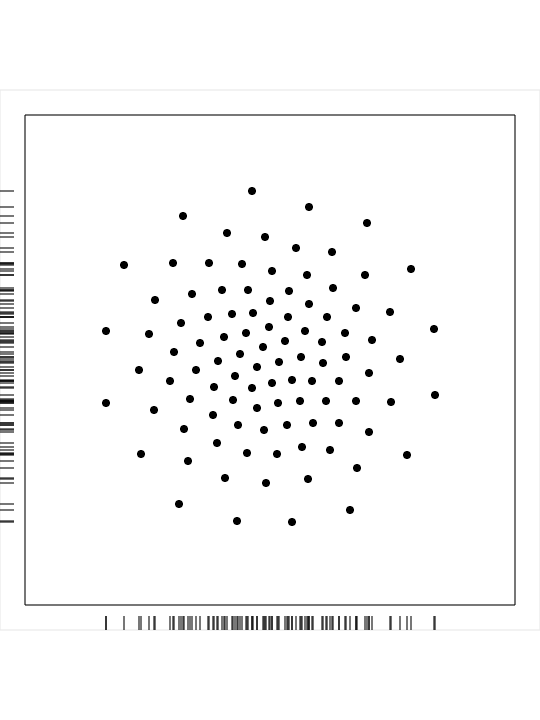
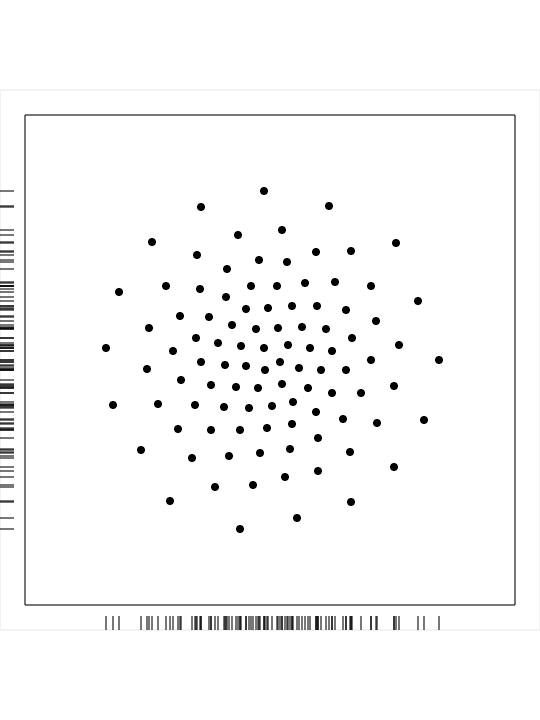
CVT_02_00100_CIRCLE is a set of 100 points generated in a circle:
CVT_NONUNI_01, CVT_NONUNI_02, and CVT_NONUNI_03 are
a set of CVT's using nonuniform density function.
The three sets are distinguished by different starting data
for the CVT iteration, generated by a Monte Carlo process.
CVT_NONUNI_04, CVT_NONUNI_05, and CVT_NONUNI_06 are
a set of CVT's using nonuniform density function.
The three sets are distinguished by different starting data
for the CVT iteration, generated by a Latin hypercube process.
CVT_02_00010, CVT_02_00100, CVT_02_01000
and CVT_02_10000 are a family of datasets in M = 2
dimensions:
-
cvt_02_00010.inp,
the input file to CVT_DATASET used to create the dataset;
-
cvt_02_00010.txt,
M = 2, N = 10, SEED = 123456789, INITIALIZE = UNIFORM,
SAMPLE = UNIFORM, SAMPLE_NUM = 500000, ITERATIONS = 100,
CHANGE = 0.001501;
-
cvt_02_00010.png,
a PNG image of
the dataset;
-
cvt_02_00100.inp,
the input file to CVT_DATASET used to create the dataset;
-
cvt_02_00100.txt,
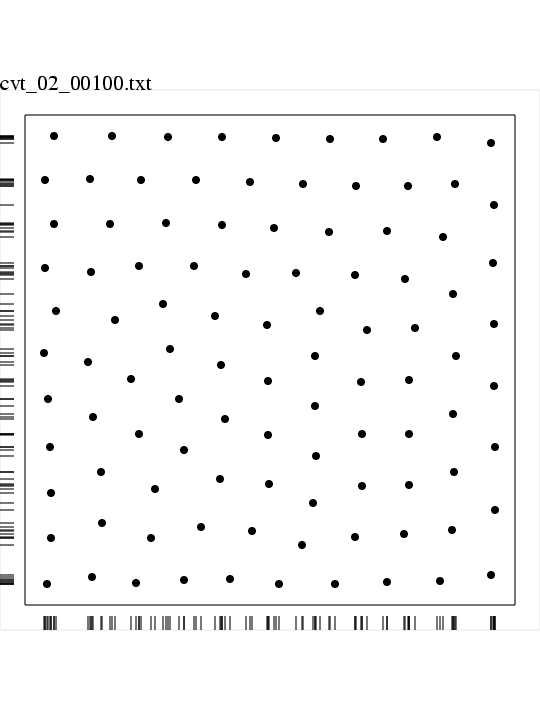
M = 2, N = 100, SEED = 123456789, INITIALIZE = UNIFORM,
SAMPLE = UNIFORM, SAMPLE_NUM = 500000, ITERATIONS = 100,
CHANGE = 0.007545;
-
cvt_02_00100.png,
a PNG image of
the dataset;
-
cvt_02_01000.inp,
the input file to CVT_DATASET used to create the dataset;
-
cvt_02_01000.txt,
M = 2, N = 1000, SEED = 123456789, INITIALIZE = UNIFORM,
SAMPLE = UNIFORM, SAMPLE_NUM = 500000, ITERATIONS = 100,
CHANGE = 0.020973;
-
cvt_02_01000.png,
a PNG image of
the dataset;
-
cvt_02_10000.inp,
the input file to CVT_DATASET used to create the dataset;
-
cvt_02_10000.txt,
M = 2, N = 10000, SEED = 123456789, INITIALIZE = UNIFORM,
SAMPLE = UNIFORM, SAMPLE_NUM = 500000, ITERATIONS = 100,
CHANGE = 0.066559;
CVT_02_00010_a, CVT_02_00100_a, and CVT_02_01000_a
are a second family of datasets in M = 2 dimensions, with
50 iterations, and 100 times as many sampling points
as family 1:
-
cvt_02_00010_a.inp,
the input file to CVT_DATASET used to create the dataset;
-
cvt_02_00010_a.txt,
M = 2, N = 10, SEED = 123456789, INITIALIZE = UNIFORM,
SAMPLE = UNIFORM, SAMPLE_NUM = 50000000, ITERATIONS = 50,
CHANGE = 0.000412;
-
cvt_02_00100_a.inp,
the input file to CVT_DATASET used to create the dataset;
-
cvt_02_00100_a.txt,
M = 2, N = 100, SEED = 123456789, INITIALIZE = UNIFORM,
SAMPLE = UNIFORM, SAMPLE_NUM = 50000000, ITERATIONS = 50,
CHANGE = 0.003668;
CVT_07_00010, CVT_07_00100, CVT_07_01000
and CVT_07_10000 is a family of datasets in M = 7 dimensions:
-
cvt_07_00010.inp,
the input file to CVT_DATASET used to create the dataset;
-
cvt_07_00010.txt,
M = 7, N = 10, SEED = 123456789, INITIALIZE = UNIFORM,
SAMPLE = UNIFORM, SAMPLE_NUM = 500000, ITERATIONS = 100,
CHANGE = 0.009351;
-
cvt_07_00100.inp,
the input file to CVT_DATASET used to create the dataset;
-
cvt_07_00100.txt,
M = 7, N = 100, SEED = 123456789, INITIALIZE = UNIFORM,
SAMPLE = UNIFORM, SAMPLE_NUM = 500000, ITERATIONS = 100,
CHANGE = 0.073011;
-
cvt_07_01000.inp,
the input file to CVT_DATASET used to create the dataset;
-
cvt_07_01000.txt,
M = 7, N = 1000, SEED = 123456789, INITIALIZE = UNIFORM,
SAMPLE = UNIFORM, SAMPLE_NUM = 500000, ITERATIONS = 100,
CHANGE = 0.442472;
-
cvt_07_10000.inp,
the input file to CVT_DATASET used to create the dataset;
-
cvt_07_10000.txt,
M = 7, N = 10000, SEED = 123456789, INITIALIZE = UNIFORM,
SAMPLE = UNIFORM, SAMPLE_NUM = 500000, ITERATIONS = 100,
CHANGE = 3.126749;
CVT_07_00010_a, CVT_07_00100_a and CVT_07_01000_a
is a second family of datasets in M = 7 dimensions, with
50 iterations, and 100 times as many sampling points
as family 1:
-
cvt_07_00010_a.inp,
the input file to CVT_DATASET used to create the dataset;
-
cvt_07_00010_a.txt,
M = 7, N = 10, SEED = 123456789, INITIALIZE = UNIFORM,
SAMPLE = UNIFORM, SAMPLE_NUM = 50000000, ITERATIONS = 50,
CHANGE = 0.006636;
-
cvt_07_00100_a.inp,
the input file to CVT_DATASET used to create the dataset;
-
cvt_07_00100_a.txt,
M = 7, N = 100, SEED = 123456789, INITIALIZE = UNIFORM,
SAMPLE = UNIFORM, SAMPLE_NUM = 50000000, ITERATIONS = 50,
CHANGE = 0.022791;
CVT_16_00010, CVT_16_00100, CVT_16_01000
and CVT_16_10000 is a family of datasets in M = 16 dimensions:
-
cvt_16_00010.inp,
the input file to CVT_DATASET used to create the dataset;
-
cvt_16_00010.txt,
M = 16, N = 10, SEED = 123456789, INITIALIZE = UNIFORM,
SAMPLE = UNIFORM, SAMPLE_NUM = 500000, ITERATIONS = 100,
CHANGE = 0.020893;
-
cvt_16_00100.inp,
the input file to CVT_DATASET used to create the dataset;
-
cvt_16_00100.txt,
M = 16, N = 100, SEED = 123456789, INITIALIZE = UNIFORM,
SAMPLE = UNIFORM, SAMPLE_NUM = 500000, ITERATIONS = 100,
CHANGE = 0.138740;
-
cvt_16_01000.inp,
the input file to CVT_DATASET used to create the dataset;
-
cvt_16_01000.txt,
M = 16, N = 1000, SEED = 123456789, INITIALIZE = UNIFORM,
SAMPLE = UNIFORM, SAMPLE_NUM = 500000, ITERATIONS = 100,
CHANGE = 1.181824;
-
cvt_16_10000.inp,
the input file to CVT_DATASET used to create the dataset;
-
cvt_16_10000.txt,
M = 16, N = 10000, SEED = 123456789, INITIALIZE = UNIFORM,
SAMPLE = UNIFORM, SAMPLE_NUM = 500000, ITERATIONS = 100,
CHANGE = 9.991355;
CVT_16_00010_a and CVT_16_00100_a is a second family of
datasets in M = 16 dimensions, with
50 iterations, and 100 times as many sampling points
as family 1:
-
cvt_16_00010_a.inp,
the input file to CVT_DATASET used to create the dataset;
-
cvt_16_00010_a.txt,
M = 16, N = 10, SEED = 123456789, INITIALIZE = UNIFORM,
SAMPLE = UNIFORM, SAMPLE_NUM = 50000000, ITERATIONS = 50,
CHANGE = 0.014803;
-
cvt_16_00100_a.inp,
the input file to CVT_DATASET used to create the dataset;
-
cvt_16_00100_a.txt,
M = 16, N = 100, SEED = 123456789, INITIALIZE = UNIFORM,
SAMPLE = UNIFORM, SAMPLE_NUM = 50000000, ITERATIONS = 50,
CHANGE = 0.046703;
CVT_16_00010_b, CVT_16_00100_b and CVT_16_01000_b
is a third family of datasets in M = 16 dimensions, with 200
iterations:
-
cvt_16_00010_b.inp,
the input file to CVT_DATASET used to create the dataset;
-
cvt_16_00010_b.txt,
M = 16, N = 10, SEED = 123456789, INITIALIZE = UNIFORM,
SAMPLE = UNIFORM, SAMPLE_NUM = 500000, ITERATIONS = 200,
CHANGE = 0.014970;
-
cvt_16_00100_b.inp,
the input file to CVT_DATASET used to create the dataset;
-
cvt_16_00100_b.txt,
M = 16, N = 100, SEED = 123456789, INITIALIZE = UNIFORM,
SAMPLE = UNIFORM, SAMPLE_NUM = 500000, ITERATIONS = 200,
CHANGE = 0.134247;
-
cvt_16_01000_b.inp,
the input file to CVT_DATASET used to create the dataset;
-
cvt_16_01000_b.txt,
M = 16, N = 1000, SEED = 123456789, INITIALIZE = UNIFORM,
SAMPLE = UNIFORM, SAMPLE_NUM = 500000, ITERATIONS = 200,
CHANGE = 1.180174;
CVT_07_00010_c, CVT_07_00100_c and CVT_07_01000_c
is a fourth family of datasets in M = 16 dimensions, which uses the
idea of GRID sampling rather than Monte Carlo:
-
cvt_16_00010_c.inp,
the input file to CVT_DATASET used to create the dataset;
-
cvt_16_00010_c.txt,
M = 16, N = 10, SEED = 123456789, INITIALIZE = UNIFORM,
SAMPLE = GRID, SAMPLE_NUM = 500000, ITERATIONS = 100,
CHANGE = 0.003192;
-
cvt_16_00100_c.inp,
the input file to CVT_DATASET used to create the dataset;
-
cvt_16_00100_c.txt,
M = 16, N = 100, SEED = 123456789, INITIALIZE = UNIFORM,
SAMPLE = GRID, SAMPLE_NUM = 500000, ITERATIONS = 100,
CHANGE = 0.024957;
-
cvt_16_01000_c.inp,
the input file to CVT_DATASET used to create the dataset;
-
cvt_16_01000_c.txt,
M = 16, N = 1000, SEED = 123456789, INITIALIZE = UNIFORM,
SAMPLE = GRID, SAMPLE_NUM = 500000, ITERATIONS = 100,
CHANGE = 0.037693;
CVT_16_00010_d, CVT_16_00100_d and CVT_16_01000_d
is a fifth family of datasets in M = 16 dimensions, which uses
a different initial seed for the random number generator, includes:
-
cvt_16_00010_d.inp,
the input file to CVT_DATASET used to create the dataset;
-
cvt_16_00010_d.txt,
M = 16, N = 10, SEED = 987654321, INITIALIZE = UNIFORM,
SAMPLE = UNIFORM, SAMPLE_NUM = 500000, ITERATIONS = 100,
CHANGE = 0.016081;
-
cvt_16_00100_d.inp,
the input file to CVT_DATASET used to create the dataset;
-
cvt_16_00100_d.txt,
M = 16, N = 100, SEED = 987654321, INITIALIZE = UNIFORM,
SAMPLE = UNIFORM, SAMPLE_NUM = 500000, ITERATIONS = 100,
CHANGE = 0.140741;
-
cvt_16_01000_d.inp,
the input file to CVT_DATASET used to create the dataset;
-
cvt_16_01000_d.txt,
M = 16, N = 1000, SEED = 987654321, INITIALIZE = UNIFORM,
SAMPLE = UNIFORM, SAMPLE_NUM = 500000, ITERATIONS = 100,
CHANGE = 1.184108;
CVT_16_00010_e, CVT_16_00100_e and CVT_16_01000_e
is a sixth family of datasets in M = 16 dimensions, which uses
double precision arithmetic:
-
cvt_16_00010_e.inp,
the input file to CVTD_DATASET used to create the dataset;
-
cvt_16_00010_e.txt,
M = 16, N = 10, SEED = 123456789, INITIALIZE = UNIFORM,
SAMPLE = UNIFORM, SAMPLE_NUM = 500000, ITERATIONS = 100,
CHANGE = 0.021418;
-
cvt_16_00100_e.inp,
the input file to CVTD_DATASET used to create the dataset;
-
cvt_16_00100_e.txt,
M = 16, N = 100, SEED = 123456789, INITIALIZE = UNIFORM,
SAMPLE = UNIFORM, SAMPLE_NUM = 500000, ITERATIONS = 100,
CHANGE = 0.139808;
-
cvt_16_01000_e.inp,
the input file to CVTD_DATASET used to create the dataset;
-
cvt_16_01000_e.txt,
M = 16, N = 1000, SEED = 123456789, INITIALIZE = UNIFORM,
SAMPLE = UNIFORM, SAMPLE_NUM = 500000, ITERATIONS = 100,
CHANGE = 1.182070;
You can go up one level to
the DATASETS directory.
Last revised on 23 February 2006.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}