random_data, a Python code which uses a random number generator (RNG) to sample points for various probability distributions, spatial dimensions, and geometries, including the M-dimensional cube, ellipsoid, simplex and sphere.
Most of these routines assume that there is an available source of pseudorandom numbers, distributed uniformly in the unit interval [0,1]. In this package, that role is played by the routine R8_UNIFORM_01, which allows us some portability. We can get the same results in a variety of languages. In general, however, it would be more efficient to use the language-specific random number generator for this purpose.
If we have a source of pseudorandom values in [0,1], it's trivial to generate pseudorandom points in any line segment; it's easy to take pairs of pseudorandom values to sample a square, or triples to sample a cube. It's easy to see how to deal with square region that is translated from the origin, or scaled by different amounts in either axis, or given a rigid rotation. The same simple transformations can be applied to higher dimensional cubes, without giving us any concern.
For all these simple shapes, which are just generalizations of a square, we can easily see how to generate sample points that we can guarantee will lie inside the region; in most cases, we can also guarantee that these points will tend to be uniformly distributed, that is, every subregion can expect to contain a number of points proportional to its share of the total area.
However, we will not achieve uniform distribution in the simple case of a rectangle of nonequal sides [0,A] x [0,B], if we naively scale the random values (u1,u2) to (A*u1,B*u2). In that case, the expected point density of a wide, short region will differ from that of a narrow tall region. The absence of uniformity is most obvious if the points are plotted.
If you realize that uniformity is desirable, and easily lost, it is possible to adjust the approach so that rectangles are properly handled.
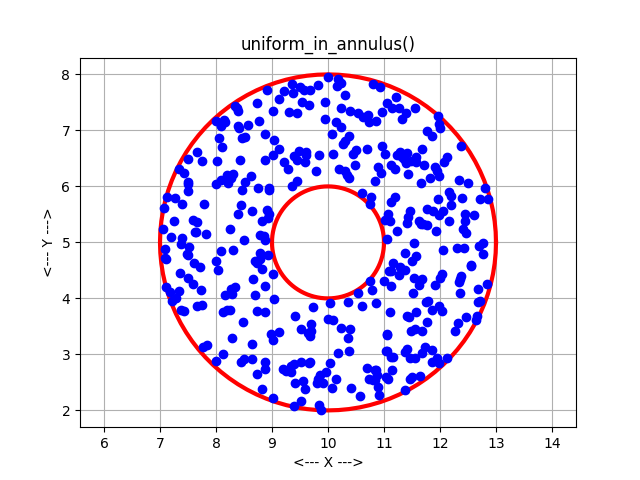
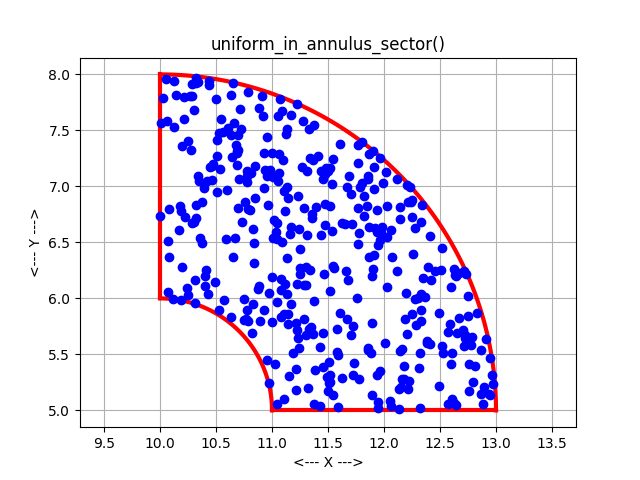
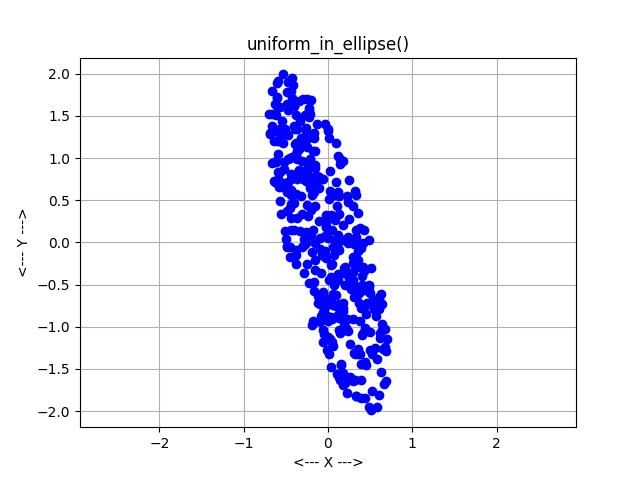
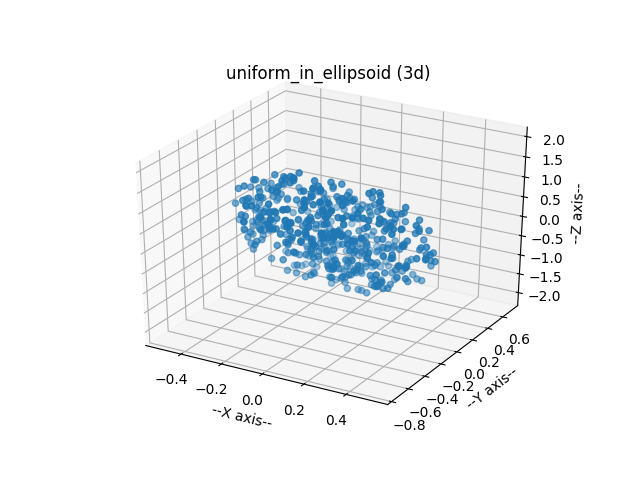
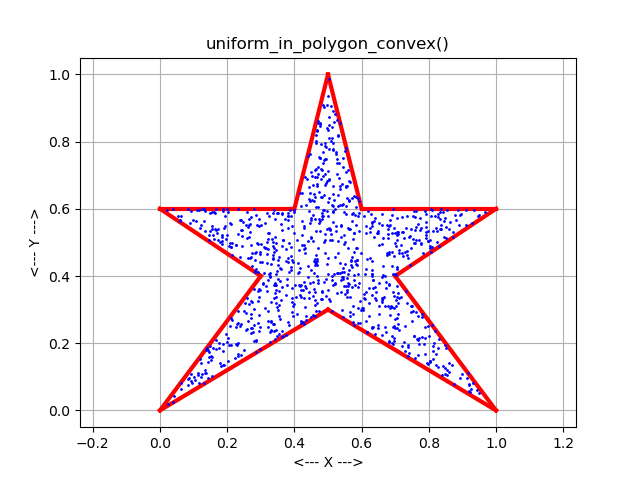
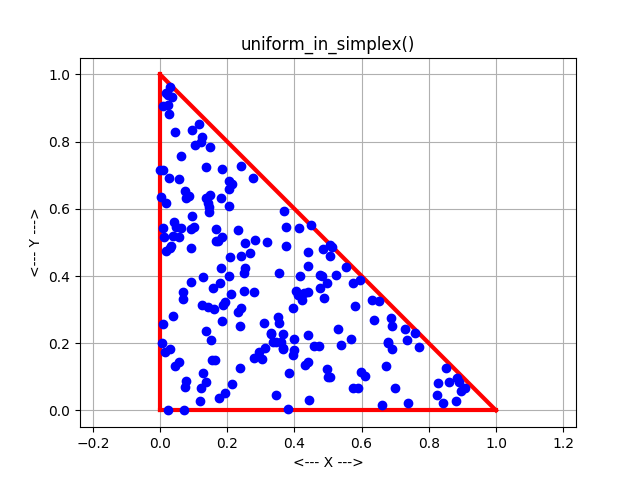
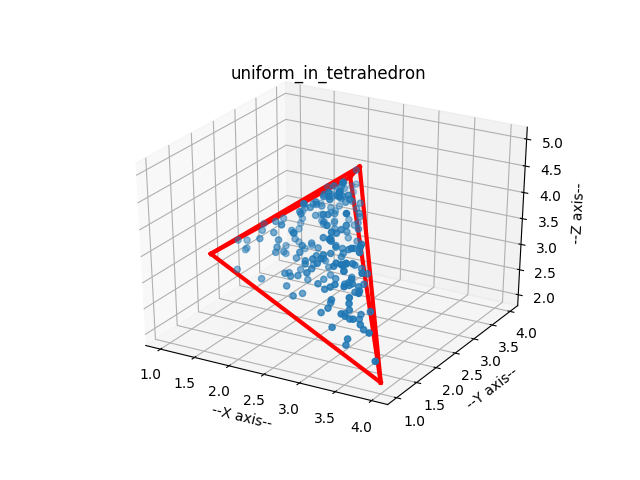
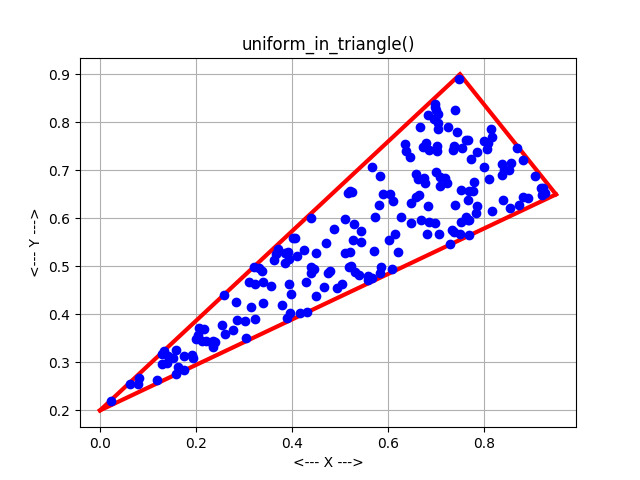
But rectangles are much too simple. We are interested in circles, triangles, and other shapes. Once the geometry of the region becomes more "interesting", there are two common ways to continue.
In the acceptance-rejection method, uniform points are generated in a superregion that encloses the region. Then, points that do not lie within the region are rejected. More points are generated until enough have been accepted to satisfy the needs. If a circle was the region of interest, for instance, we could surround it with a box, generate points in the box, and throw away those points that don't actually lie in the circle. The resulting set of samples will be a uniform sampling of the circle.
In the direct mapping method, a formula or mapping is determined so that each time a set of values is taken from the pseudorandom number generator, it is guaranteed to correspond to a point in the region. For the circle problem, we can use one uniform random number to choose an angle between 0 and 2 PI, the other to choose a radius. (The radius must be chosen in an appropriate way to guarantee uniformity, however.) Thus, every time we input two uniform random values, we get a pair (R,T) that corresponds to a point in the circle.
The acceptance-rejection method can be simple to program, and can handle arbitrary regions. The direct mapping method is less sensitive to variations in the aspect ratio of a region and other irregularities. However, direct mappings are only known for certain common mathematical shapes.
Points may also be generated according to a nonuniform density. This creates an additional complication in programming. However, there are some cases in which it is possible to use direct mapping to turn a stream of scalar uniform random values into a set of multivariate data that is governed by a normal distribution.
Another way to generate points replaces the uniform pseudorandom number generator by a quasirandom number generator. The main difference is that successive elements of a quasirandom sequence may be highly correlated (bad for certain Monte Carlo applications) but will tend to cover the region in a much more regular way than pseudorandom numbers. Any process that uses uniform random numbers to carry out sampling can easily be modified to do the same sampling with a quasirandom sequence like the Halton sequence, for instance.
The code includes a routine that can write the resulting data points to a file.
The information on this web page is distributed under the MIT license.
random_data is available in a C version and a C++ version and a Fortran77 version and a Fortran90 version and a MATLAB version and a Octave version and a Python version.
asa183, a Python code which implements the Wichman-Hill pseudorandom number generator.
ball_grid, a Python code which computes grid points that lie inside a ball.
ring_data, a Python code which creates, plots, or saves data generated by sampling concentric, possibly overlapping rings.
simplex_coordinates, a Python code which computes the Cartesian coordinates of the vertices of a regular simplex in M dimensions.
tetrahedron_grid, a Python code which computes a tetrahedral grid of points.
triangle_grid, a Python code which computes a triangular grid of points.
uniform, a Python code which samples the uniform random distribution.
van_der_corput, a Python code which computes elements of a 1D van der Corput Quasi Monte Carlo (QMC) sequence using a simple interface.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}