clustering, a dataset directory which contains example datasets used for clustering.
The computer code and data files described and made available on this web page are distributed under the GNU LGPL license.
HARTIGAN, a dataset directory which contains datasets for testing clustering algorithms;
MARTINEZ, a dataset directory which contains datasets for computational statistics, including cluster analysis;
PCL, a dataset directory which contains datasets from a gene expression experiment on Arabidopsis, which are candidates for data cluster analysis;
SPAETH, a dataset directory which contains datasets for cluster analysis;
SPAETH2, a dataset directory which contains datasets for cluster analysis;
faithful_data records 272 observations of eruptions of the Old Faithful geyser, recording eruption length and eruption wait in minutes.
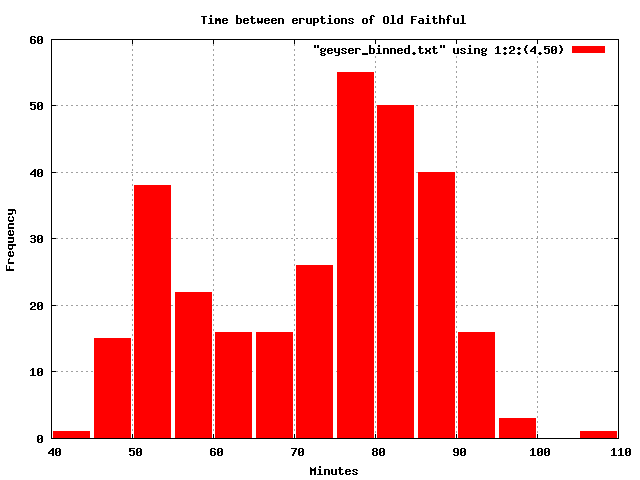
geyser_data contains the waiting time in minutes between successive eruptions of the Old Faithful geyser. 299 values are recorded. The data ranges from 43 to 108. The data comes from Martinez and Martinez.
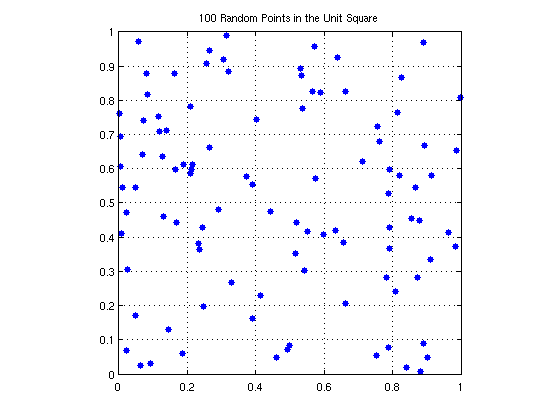
hundred_data contains (x,y) data points within 0 <= x <= 1, 0 <= y <= 1. There are 100 values.
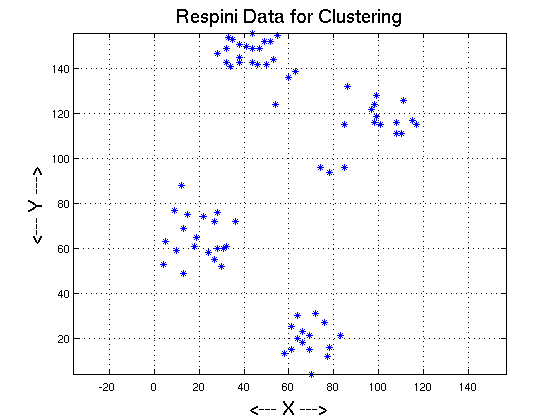
ruspini_data contains (x,y) data points within 0 <= x <= 120, 0 <= y <= 160. There are 75 values. The data comes from Kaufmann and Rousseeuw Martinez and Martinez.
{kind=link}
{kind=link}
{kind=link}
{kind=link}